requests라는 사용해주고
내용만을 추출하고싶을 때
뷰티풀숲이라는걸 사용해줌
내용(resp)을 뷰티풀 숲에 인풋해줌
아놔ㅡㅡ find함수 잘안씀 ㅡㅡ
어제배운거 test_bsoup4_01
test_bsoup_02.py
find라는걸 보다는 select() 라는 거를 더 많이 씀
select결과를 리스트로 받아온다
title이 리스트임 리스트인데 .text하면 에러가 남
리스트인데 어떻게 텍스트로 바꿔 그래서 리스트니까
데이터 하나밖에 없으니까 print(title[0].text)해준거임 text안해주고 보면 ]괄호로 온게 보임

만약에 내용을 긁는데 쓰잘데기없는 것 까지 긁어와졌다?
그러면 다시 봐서 세부적인 곳을 열어서 태그명과 선택자 긁어온다.
strip() 썼는데 공백제거 안해주는건
내용안에 있는건 사이사이에 있는건? 제거 할수 없고 데이터 앞뒤로 공백 제거 할 수 있다.

더깔끔하게 해줄라면 또 더 세부적으로 들어가야함
p 태그는 단락을 나눌때
파란색은 본문 주황색은 여백
div#harmornyContainer
ㄴ <section> (얘로는 못글거 dmcf-pid)
ㄴ <p> 본문 내용 1번째 단락
ㄴ <p> 본문 내용 1번째 단락
ㄴ <p> 본문 내용 1번째 단락
ㄴ <p> 본문 내용 1번째 단락 >>p태그하나씩가지고와서 합치면 깔끔하게 됌
자손선택자로 끄내면 됌
a = > 앵커 태그
하이퍼링크 해주는 에이태그에있는걸루 가지고오면 주소가 싹 복사됌

resp가 뷰티풀 슾으로 인풋 : 타이틀이나 내용을 뽑을때 사용하는 거

title 에 담아놓은 슾.셀렉트 h3.tit_view만 가져와서 타이틀에 담아 놓음

>>>>>>newone
>>>>>>>>>newspage
하모니컨테이너에서 자손이 p인거를 다 셀렉 한것
본문에있는 p태그를 원하니까 하모니컨테이너가 그 p를 감싸고 있으니까

select은 한건이든 몇건이든 리스트로 저장이 됌

내가 원하는 부분에 a태그link_txt를 셀렉해주세요

a에서 href 하나씩 꺼내주세요
한건의 기사를 할라먼 기사의 주소가 필요한데
하나하나 a에 herf에 주소가 되어있으니까 가져오면.,,됌.a.href
사랑방 부동산
게시판에있는 게시글에가서 먼저 제목이랑 내용을 긁어봐
그게 완료가 되면 게시글 전체한페이지 내에있는
게시글 제목+내용 완벽하게 됐다
하면 페이지 이동해서 제목내용 뽑는걸 해봐
내가 이싸이트를 긁어도 되나 안되나를 확인할 수 있는 방법이 있음
주소robots.text 다운 받ㅇ보고
크롤링할 때의 허용 범위
Disallow : / 슬러쉬 밑으로긁지말라
Allow /$ 메인페이지만 가능하고 나머지 안댐
Disallow있는 곳은 긁으면 안되고
Allow만 가능 >> 강제성을 띄는건 아니고 접근 규칙같은거 경고한거임 연습할때만 좀 괜춘고
수익성, 영리적인 목적으로하면 법적 책임 짐
비영리일때 봐주는 느낌 아닐수도 있고
robots.txt가 없다고 막 긁어는것도 안댐
>>>회사가서 긁을때 확인하고 긁어라는 것
네이버나 다음같은 경우는 계속 크롤링하면 ip차단 해버림
실시간으로 크롤링하게 해놨어 그러면 특정한 아이피가 일초에 몇번씩 접속하는거지?하고 차단함 네이버나 다음은
dt가 데이트에 약자로 많이 쓰임
p 태그가 나왔을때는 반복문을 돌리면된다는 생각이 나도록!

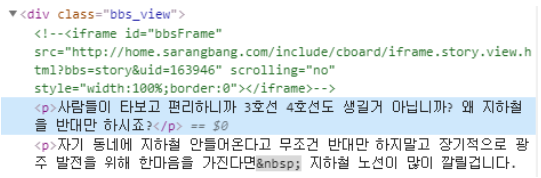
i 에 <p>태그 하나씩 들어가는 것임 그래서 text < 안에 텍스트만
strip() 위 아래 여백 없애주는 거 잘 모르겟으면
content +=i < 이거만해서 print하고 콘솔창에서 확인!!!!!
daum > newsone > newslist > newpage
apart > boardone(부동산 게시글)
1999.11.02 : [:10] 하면 되는데
1999.11.5이렇게 되어있으면 (사이즈가 고정이 되어있지 않아)
년월일 끝났을땐 ㅏ오는걸 보면도ㅐㅁ
, 가 오면 인덱스로 ,가 오는 번호를 찾아서 [ : *]
(*) > 인덱스
뷰티풀 숲을쓰다가 안긁어지는거 이;ㅆ는데 댓글같은경우
엔터를 너무 많이친게 안가지거와지면
셀레니움같은걸로 해주먼 댐
다음 같은 거는 페이지는 나오는데 에러는 안나서 if문 넣어준건데
다른데에서는 아예에러가 뜰수도 잇음 404그러면 이제 스테이터스 코드 != 200 : << 로 해주면 된다.

'Python' 카테고리의 다른 글
| 20.06.18 mongodb 클래스생성하고 저장하는 부분 (0) | 2020.08.29 |
|---|---|
| 20.06.17 뷰티풀 슾으로 웹크롤링 + selenium으로도 해봄 (0) | 2020.08.29 |
| 20.06.12 (0) | 2020.08.29 |
| 20.06.30 (0) | 2020.08.29 |
| Mongo DB에 관한 것 정리 (0) | 2020.08.29 |